
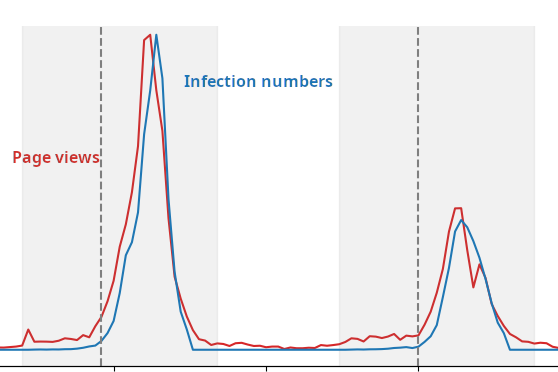
Infection numbers peak shortly after page views on certain Wikipedia articles.
Forecasting the course of an epidemic helps in fighting it. Most predictions are based on current infection numbers. But those can be hard to get. Search patterns and page views can act as substitutes.
October through May is flu season. Every year the, US Centers for Disease Control and Prevention (CDC) hosts a challenge for research teams to predict the course of infection numbers for this period. Most partaking oracles rely on current numbers to predict the future. But not everyone who is sick will visit a doctor, nor are all patients tested for the virus. In the end, not all cases are counted and also the numbers come in with a delay. We need good proxies to overcome those shortcomings.
Computer Science and Epidemics
Cristian Consonni is an Italian computer scientist who had nothing to do with epidemics at the beginning of his doctorate studies. He was looking for information hidden in Wikipedia’s structure – in the links between articles rather than in the words themselves. While doing his literature research he came across a publication whose authors took the page views on Wikipedia articles and combined them with official influenza numbers to train computer algorithms and predict future scenarios. It is possible to do that because people who feel sick search the internet for symptoms and often end up on the encyclopedia’s pages.
Guided by his advisor and helped by an undergrad student, Consonni wanted to repeat the study and extend it to other languages. But in contrast to the original authors, he wanted to select the relevant articles automatically, without the need for medical experts. Consonni thought it would only need “a little bit of work” as he wrote on Twitter. Then he adds: “‘a little bit of work’ took 4+ years end-to-end, btw”.
One of the reasons for the long delay was the missing code. “We didn’t know exactly what they did” says Consonni about the original authors. It means that he had to rewrite the software first to be able to reproduce their numbers. Only then can he compare his automatic selection of terms with that of medical experts.
Automatic Curation
To select the relevant words Dr. Consonni and his colleagues chose those which link to “Influenza” but also have a short path back. For example, both “Superinfection” and “Ben Turpin” link directly to “Influenza”, the latter because the silent film actor’s wife lost her hearing due to the flu. However, only one click is necessary to return from “Superinfection” but at least four in the case of “Ben Turpin” (virus subtype “H1N1” was declared a national emergency by “Barack Obama” who attended “Occidental College” where a movie with Turpin was shot). The so-called Cyclerank reflects this idea: “Superinfection” ranks much higher than “Ben Turpin”.
Consonni trained their algorithm with the page views on the hundred highest ranking pages. It turns out that the predictions are on par with older methods. “It is not world-shaking” Consonni recognizes. But one huge advantage is that now the chosen Wikipedia entries are objective: they are independent of manual curation, can easily be selected for other languages, and can be updated when Wikipedia changes.
Infections or Media Coverage, What Drives Attention?
But one problem remains unsolved: is a growing click rate caused by rising infections or did media coverage raise the readers’ interest? Consonni says: “We tried to account for that. But to be fair, it’s very difficult to get reliable or even good data sets with the news.” The problem needs a different solution.
So Consonni went to the epidemiology department for help where one group was trying to understand how knowledge about diseases spreads mouth-to-mouth. And what is the role of media coverage? Promising results for the 2014 Ebola crisis and the 2015 Zika epidemic lead to a draft for a paper.
However: “that paper had quite an unfortunate life.” After one year under review, the editors rejected it because it didn’t fit with the journal, not for any shortcomings of the paper itself. What might be disappointing for the researchers is not really unusual. The group then wanted to prepare the results for a different journal. “Then COVID happened and all my epidemiology colleagues have been super busy since last year. This paper is now on a shelf.”
©Niko Komin (@kokemikal)